
随着足球运动的全球普及和数据分析技术的飞速发展,预测大型足球赛事如欧洲杯的冠军已成为一个复杂而引人入胜的课题。本文将探讨如何通过数据分析和机器学习技术来构建一个有效的欧洲杯冠军预测模型。
任何预测模型的基础都是数据。对于欧洲杯冠军预测,我们需要收集包括但不限于以下几类数据:
在收集到数据后,预处理是关键步骤,包括数据清洗、缺失值处理、异常值检测等,以确保数据的质量和准确性。
特征工程是构建预测模型的核心环节,它涉及到如何从原始数据中提取有用的信息,并将其转换为模型可以理解的格式。例如,可以将球队的平均控球率、射门成功率等统计数据作为特征。还可以考虑引入一些高级特征,如球队之间的历史交锋记录、球队在特定天气条件下的表现等。
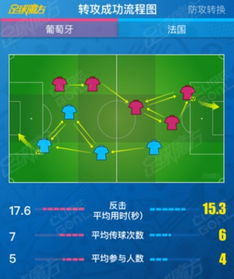
在特征工程完成后,接下来是选择合适的机器学习模型进行训练。常用的模型包括逻辑回归、支持向量机(SVM)、随机森林、梯度提升机(GBM)和神经网络等。选择模型时需要考虑数据的特性、模型的复杂度以及预测的准确性。
模型训练过程中,交叉验证是必不可少的步骤,它可以帮助我们评估模型的泛化能力,避免过拟合。
模型训练完成后,需要通过一系列评估指标来衡量模型的性能,如准确率、召回率、F1分数等。如果模型的表现不理想,可能需要回到特征工程阶段,重新考虑特征的选择或创建新的特征。模型的参数调优也是提高模型性能的重要步骤。
在模型经过充分训练和优化后,就可以用来预测即将到来的欧洲杯冠军。预测结果需要结合实际情况进行分析,考虑可能影响比赛结果的外部因素,如球队状态、伤病情况、战术调整等。
通过数据分析和机器学习技术,我们可以构建一个相对准确的欧洲杯冠军预测模型。然而,足球比赛的不确定性和复杂性意味着任何预测都存在一定的风险。因此,预测结果应谨慎使用,并结合专家意见和实时数据进行调整。
欧洲杯冠军预测不仅是一个技术挑战,也是对足球运动深度理解的体现。通过不断的数据分析和模型优化,我们可以更接近于揭示足球比赛背后的规律,为球迷和分析师提供有价值的参考。

在足球的世界里,球星们不仅是场上的英雄,也是公众人物,他们的行为举止...
直播吧9月12日讯拉齐奥主帅巴罗尼接受了媒体的采访,对球队新援、阿森...

直播吧9月20日讯本轮中超北京国安客场3-1战胜梅州客家。第88分钟...

都说穷则思变,早就烂到根上的中国男足在世预赛遭遇耻辱性连败之后,对人...

北京时间9月23号,陈梦解锁“校长”身份,孙颖莎王楚钦也有新身份,马...
